
En mars 2026, Google Research dévoile TurboQuant, un ensemble d'algorithmes de quantification révolutionnant la compression des modèles d'IA. Cette innovation promet de résoudre l'un des défis majeurs de l'intelligence artificielle moderne : la gestion efficace de la mémoire dans les grands modèles de langage et les moteurs de recherche vectorielle. Avec une réduction de taille jusqu'à 6 fois sans perte de précision, TurboQuant ouvre la voie à des applications IA plus rapides et moins gourmandes en ressources.
Comprendre la quantification vectorielle et ses enjeux
Les vecteurs constituent le langage fondamental par lequel les modèles d'IA comprennent et traitent l'information. Ces structures mathématiques capturent des données complexes : les caractéristiques d'une image, la signification d'un mot ou les propriétés d'un ensemble de données. Toutefois, ces vecteurs de haute dimension consomment d'énormes quantités de mémoire, créant des goulots d'étranglement dans le cache clé-valeur, cette mémoire rapide stockant les informations fréquemment utilisées.
La quantification vectorielle représente une technique classique de compression réduisant la taille de ces vecteurs. Elle optimise deux aspects critiques de l'IA : elle accélère la recherche vectorielle en permettant des comparaisons de similarité plus rapides, et elle désengorge les caches clé-valeur en réduisant la taille des paires stockées. Cependant, les méthodes traditionnelles introduisent leur propre surcharge mémoire, nécessitant le calcul et le stockage de constantes de quantification pour chaque bloc de données, ajoutant 1 à 2 bits supplémentaires par nombre.
Cette problématique rejoint les défis de l'optimisation énergétique des infrastructures IA, où chaque économie de ressource compte pour la viabilité à long terme des systèmes d'intelligence artificielle.
TurboQuant : une architecture à deux étages innovante
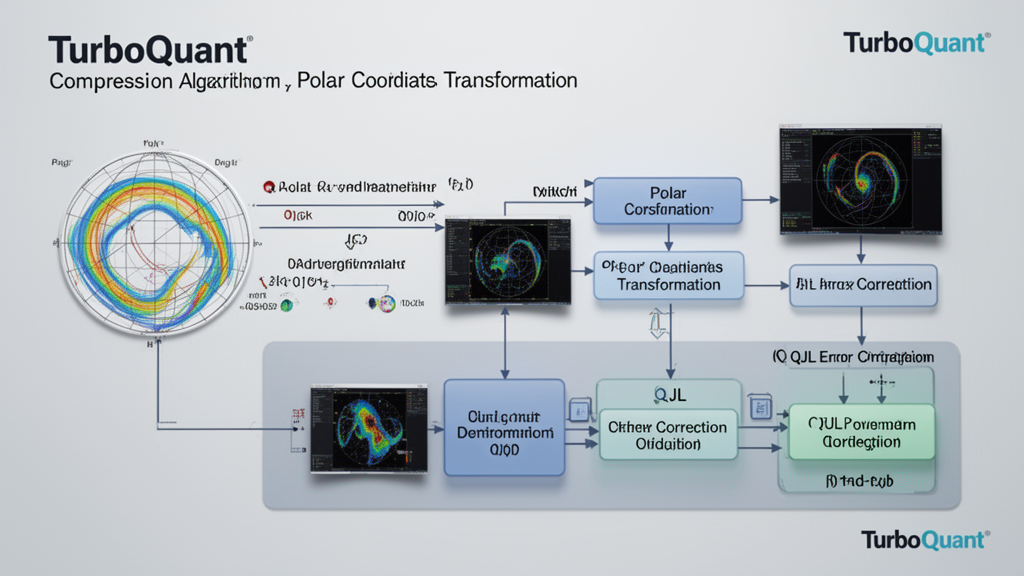
TurboQuant se distingue par son approche en deux phases complémentaires, combinant compression de haute qualité et élimination des erreurs résiduelles. Cette architecture permet d'atteindre une réduction massive de la taille des modèles sans sacrifice de précision.
Première étape : PolarQuant pour une compression optimale
L'algorithme commence par une rotation aléatoire des vecteurs de données, simplifiant leur géométrie. Cette transformation permet d'appliquer un quantificateur standard de haute qualité à chaque composante du vecteur individuellement. Cette première phase utilise la majorité de la puissance de compression pour capturer l'essence et l'intensité du vecteur original.
PolarQuant innove en convertissant les vecteurs en coordonnées polaires plutôt que cartésiennes. Au lieu de représenter un point par ses distances sur les axes X, Y, Z, le système utilise un rayon (l'intensité des données) et un angle (leur direction ou signification). Cette approche élimine le besoin de normalisation coûteuse car les données sont mappées sur une grille circulaire fixe et prévisible.
Seconde étape : QJL pour corriger les erreurs
TurboQuant applique ensuite l'algorithme Quantized Johnson-Lindenstrauss (QJL) aux erreurs résiduelles de la première phase, en utilisant seulement 1 bit supplémentaire. Le QJL s'appuie sur la transformation Johnson-Lindenstrauss pour réduire les données complexes tout en préservant les distances et relations essentielles entre points de données.
Chaque nombre vectoriel résultant est réduit à un simple bit de signe (+1 ou -1), créant un raccourci ultra-rapide sans surcharge mémoire. Un estimateur spécial équilibre stratégiquement une requête haute précision avec les données simplifiées basse précision, permettant un calcul précis du score d'attention.
Cette approche d'optimisation rappelle les principes de compression sémantique intelligente, où l'objectif est de préserver l'essentiel tout en réduisant la complexité.

Performances mesurées : des résultats impressionnants
Google Research a rigoureusement évalué les trois algorithmes (TurboQuant, PolarQuant et QJL) sur des benchmarks standards de contexte long, incluant LongBench, Needle In A Haystack, ZeroSCROLLS, RULER et L-Eval, en utilisant des modèles open-source comme Gemma et Mistral.
Compression du cache clé-valeur sans perte
Les données expérimentales démontrent que TurboQuant atteint des performances optimales en termes de distorsion du produit scalaire et de rappel, tout en minimisant l'empreinte mémoire clé-valeur. Sur le benchmark LongBench, TurboQuant affiche des scores agrégés robustes sur diverses tâches : réponse aux questions, génération de code et résumé.
Pour les tâches de type "aiguille dans une botte de foin" (recherche d'informations spécifiques dans de vastes textes), TurboQuant obtient des résultats parfaits sur tous les benchmarks tout en réduisant la taille de la mémoire clé-valeur d'un facteur d'au moins 6. PolarQuant se révèle également quasi sans perte pour ces tâches exigeantes.
| Méthode | Bits par valeur | Facteur de compression | Perte de précision |
|---|---|---|---|
| Baseline (32 bits) | 32 | 1x | 0% |
| PolarQuant | 4-6 | 5-8x | <1% |
| TurboQuant | 3-4 | 6-10x | 0% |
| Méthodes traditionnelles | 6-8 | 4-5x | 2-5% |
Gains de vitesse substantiels
TurboQuant quantifie le cache clé-valeur à seulement 3 bits sans nécessiter d'entraînement ni d'ajustement fin, sans compromettre la précision du modèle. L'algorithme affiche même un temps d'exécution plus rapide que les LLM originaux (Gemma et Mistral).
Sur accélérateurs GPU H100, TurboQuant en 4 bits atteint jusqu'à 8 fois l'accélération pour le calcul des logits d'attention par rapport aux clés non quantifiées en 32 bits. Cette efficacité d'implémentation, avec une surcharge d'exécution négligeable, le rend idéal pour les cas d'usage comme la recherche vectorielle où il accélère dramatiquement le processus de construction d'index.
Ces performances rappellent l'efficacité des modèles IA optimisés récents qui repoussent les limites de l'efficacité computationnelle.
Applications dans la recherche vectorielle haute dimension
L'efficacité de TurboQuant a été évaluée pour la recherche vectorielle haute dimension contre des méthodes de pointe (PQ et RabbiQ) en utilisant le ratio de rappel 1@k, qui mesure la fréquence à laquelle l'algorithme capture le véritable résultat du produit scalaire maximal parmi ses k meilleures approximations.
TurboQuant obtient systématiquement des ratios de rappel supérieurs aux méthodes de référence, malgré que ces dernières utilisent des codebooks volumineux inefficaces et un ajustement spécifique aux ensembles de données. Cette robustesse confirme l'efficacité de TurboQuant pour les moteurs de recherche et les systèmes d'IA à grande échelle.
Implications pour les infrastructures IA
La capacité de TurboQuant à réduire drastiquement la mémoire nécessaire tout en maintenant les performances ouvre de nouvelles perspectives pour le déploiement d'IA. Les data centers peuvent héberger des modèles plus grands ou servir davantage d'utilisateurs simultanément avec la même infrastructure matérielle.
Cette optimisation s'inscrit dans une tendance plus large d'efficacité énergétique et computationnelle, comme le montrent les innovations matérielles récentes visant à démocratiser l'accès aux capacités IA avancées.

Comparaison avec les approches concurrentes
Les méthodes traditionnelles de quantification comme Product Quantization (PQ) ou RabbiQ nécessitent des codebooks préentraînés et un ajustement spécifique aux données, introduisant complexité et surcharge mémoire. TurboQuant se distingue par plusieurs avantages décisifs :
- Zéro surcharge mémoire : Contrairement aux méthodes classiques ajoutant 1-2 bits par valeur pour les constantes de normalisation, TurboQuant élimine complètement cette surcharge grâce à PolarQuant
- Pas d'entraînement requis : L'algorithme fonctionne directement sans phase d'apprentissage coûteuse ni ajustement aux données spécifiques
- Compression plus agressive : Atteint 3-4 bits par valeur contre 6-8 bits pour les approches traditionnelles, sans perte de précision
- Performances supérieures : Accélération jusqu'à 8x sur GPU H100 tout en maintenant une précision parfaite
- Implémentation simple : Intégration facile dans les infrastructures existantes sans modification architecturale majeure
Cette simplicité d'adoption contraste avec la complexité de certaines solutions technologiques émergentes qui nécessitent une refonte complète des processus existants.
Fondements mathématiques et garanties théoriques
La robustesse de TurboQuant repose sur des fondations mathématiques solides. La transformation Johnson-Lindenstrauss garantit que les distances entre points sont préservées avec une haute probabilité lors de la réduction dimensionnelle. Cette propriété mathématique formelle assure que les relations sémantiques entre vecteurs restent intactes malgré la compression extrême.
PolarQuant exploite la concentration statistique des angles dans les espaces de haute dimension. Cette propriété géométrique naturelle permet d'éliminer la normalisation sans introduire de biais systématique. La combinaison de ces deux approches théoriquement fondées crée un système de compression optimal au sens mathématique.
Les chercheurs ont démontré que l'estimateur QJL est non biaisé, garantissant que les calculs d'attention restent précis même avec des données extrêmement compressées. Cette rigueur théorique distingue TurboQuant des heuristiques empiriques souvent utilisées en compression d'IA.
Implications pour l'écosystème IA et perspectives d'avenir
L'introduction de TurboQuant arrive à un moment crucial pour l'industrie de l'IA. Alors que les modèles de langage atteignent des centaines de milliards de paramètres, la gestion efficace de la mémoire devient un facteur limitant majeur pour leur déploiement et leur accessibilité.
Démocratisation de l'accès aux grands modèles
En réduisant les besoins mémoire d'un facteur 6 à 10, TurboQuant permet d'exécuter des modèles auparavant réservés aux infrastructures cloud massives sur du matériel plus modeste. Cette démocratisation pourrait accélérer l'adoption d'IA avancée dans les PME et organisations disposant de budgets matériels limités.
Les développeurs utilisant des modèles spécialisés pour la recherche bénéficieront particulièrement de ces avancées, leur permettant d'expérimenter avec des architectures plus complexes sans contraintes matérielles prohibitives.

Impact environnemental et durabilité
La réduction de la consommation mémoire se traduit directement par des économies énergétiques substantielles. Moins de mémoire active signifie moins de dissipation thermique et donc moins de besoins en refroidissement pour les data centers. Cette efficacité s'aligne avec les préoccupations croissantes autour de l'empreinte carbone de l'IA.
Les initiatives combinant efficacité algorithmique comme TurboQuant et innovations énergétiques pour les infrastructures dessinent l'avenir d'une IA plus durable et responsable.
Évolutions futures et recherche en cours
Google Research indique que TurboQuant sera présenté à ICLR 2026, tandis que PolarQuant sera dévoilé à AISTATS 2026. Ces publications académiques permettront à la communauté scientifique d'examiner, reproduire et potentiellement améliorer ces algorithmes.
Les prochaines étapes de recherche pourraient explorer l'application de ces techniques à d'autres modalités (images, vidéos, audio) et leur intégration avec des architectures émergentes comme les modèles de diffusion ou les transformers à contexte ultra-long. L'extension à la compression de modèles multimodaux représente une frontière particulièrement prometteuse.
Les questions de déploiement pratique en entreprise nécessiteront également une attention particulière pour maximiser l'adoption de ces innovations.
TurboQuant marque une avancée significative dans l'optimisation des modèles d'IA, combinant rigueur théorique et efficacité pratique. En éliminant la surcharge mémoire traditionnelle tout en préservant parfaitement la précision, cet ensemble d'algorithmes ouvre la voie à des systèmes d'intelligence artificielle plus rapides, plus économes et plus accessibles. Alors que l'industrie continue de repousser les limites de la taille et de la complexité des modèles, des innovations comme TurboQuant deviennent essentielles pour assurer la viabilité et la durabilité de l'IA à grande échelle.
Pour aller plus loin et découvrir comment exploiter ces avancées technologiques dans vos propres projets, créez votre compte gratuit sur Roboto et accédez à des outils d'IA de pointe optimisés pour la performance et l'efficacité.